
人工智能(Artificial Intelligence,AI)真的能超越人類智慧?全球矚目的人機世紀大戰於 3 月 9 日展開首場對奕,Google 人工智能系統 AlphaGo 擊敗世界棋王李世石,象徵 AI 已晉升到另一層次,令人深思人類與機械人的關係。
人機對奕採 5 局 3 勝制
Google 旗下 DeepMind 開發的人工智能系統 AlphaGo,在韓國首爾與 18 度榮獲世界棋王銜頭、圍棋九段棋士李世石對戰,李世石最終投降。比賽在 YouTube 直播,由全球有幾十萬人在線觀看。AlphaGo 與李世石共對奕 5 盤,勝者可拿到 100 萬美元獎金;若 Google 拿到會捐給慈善機構。餘下 4 盤將於 3 月中陸續展開。
繼 IBM 的電腦「深藍」(Deep Blue)在 1997 年擊敗國際象棋世界冠軍 Garry Kasparov 後,今次再有超級電腦在棋盤上戰勝世界級棋王。不過對電腦來說,圍棋卻比國際象棋複雜得多。

圍棋可衍生出最多 3,361 種局面,棋局變化遠勝國際象棋。
圍棋變化遠超國際象棋
棋盤未被下子前,先手有 361 個可選的下子方案。棋局展開後,圍棋可衍生出最多 3,361 種局面,國際象棋則頂多只有 2,155 種局面,所以前者有著比國際象棋更多的選擇空間、布局變化更大,對人工智能的挑戰也特別大,因此圍棋已成為一眾人工智能專家極欲挑戰的研究項目。
傳統人工智能的運算方式是,將所有可能的棋子走法構建成一棵搜索樹(Search Tree),但此方式卻未能應付棋局變化萬千的圍棋。於是 Google 便把高級搜索樹與深度神經網絡(deep neural network)結合起來,架構成 AlphaGo 系統。AlphaGo 內含 2 組深度神經網絡,分別是選擇下一步走法的策略神經網絡(policy network),以及推算棋局變化的價值神經網絡(value network)。
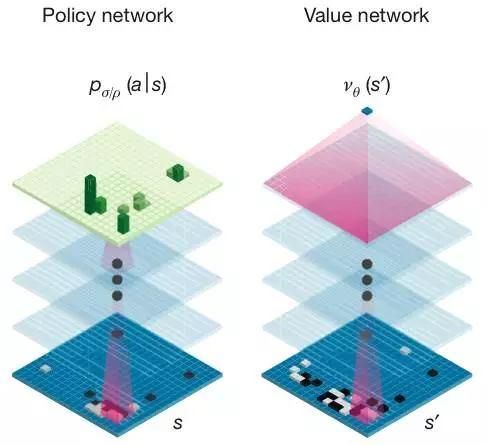
AlphaGo 內含 2 組深度神經網絡,分別是策略神經網絡(policy network)和價值神經網絡(value network)。
AlphaGo 賽前已做足準備工夫
Google 替 AlphaGo 輸入人類圍棋高手的 3,000 萬步圍棋走法,以訓練神經網絡;同時,AlphaGo 亦在神經網絡之間運行數千局圍棋,學習自主探索新的圍棋策略。結果,系統成長至具備足夠能力擊敗大部分具有龐大搜尋樹的圍棋運算程式。
後來,Google 更安排 AlphaGo 於 2015 年 10 月跟歐洲圍棋冠軍樊麾(Fan Hui)閉門比賽,最終以 5-0 獲勝。由於可見,AlphaGo 在挑戰李世石之前,已做足準備工夫,奠定致勝的基礎!

圍棋世界棋王李世石(右)在對奕前顯得躊躇滿志。
台灣博士當 AlphaGo 替手
原來代 AlphaGo 下棋的棋手亦殊不簡單。他的名字是黃士傑,乃台灣土生土長的資訊工程博士,畢業於台灣師範大學,更是 AlphaGo 研發團隊的成員之一。黃氏本身既是圍棋好手,2007 年時便擁有圍棋業餘 6 段資格,也是人工智能的專家,其博士畢業論文正是以 AI 「應用於電腦圍棋之蒙地卡羅樹搜尋法的新啟發式演算法」。
黃士傑今次由幕後走到幕前,親自坐到棋盤前,充當 AlphaGo 下棋的「手」,幫助 AlphaGo 首戰擊敗李世石,可說是與有榮焉。
AI+無人機=無限潛能
人工智能應用的可能性極多,在無人機上也能找到其蹤影。如 Facebook 開發 Aquila 無人機,打算運用 AI 系統,飛到偏僻地區,精準地找出人口聚集點,空中廣播網絡訊號,為當地人提供上網服務;瑞士蘇黎世大學則研發可供無人機使用的人工智能系統,能分辨出森林中的道路,引領無人機前進,協助尋找迷路登山客。Google 未來會否也一樣,將 AlphaGo 的 AI 技術應用在旗下無人機呢?
人機世紀對弈賽期一覽
- 第一場次對弈:2016 年 3 月 9 日(三) ,中午 12 點。
- 第二場次對弈:2016 年 3 月 10 日(四),中午 12 點。
- 第三場次對弈:2016 年 3 月 12 日(六),中午 12 點。
- 第四場次對弈:2016 年 3 月 13 日(日),中午 12 點。
- 第五場次對弈:2016 年 3 月 15 日(二),中午 12 點。
▼ Google AlphaGo 首戰擊敗韓國天才圍棋棋王李世石的精采影片。
▼ Google AlphaGo 人工智能系統解說





